The Missing Context Layer for AI Agents Over Business Data
Why we rebuilt Wren Engine from a context layer into an open context engine, and what we learned along the way

Howard Chi
Updated: Apr 02, 2026
Published: Apr 02, 2026

AI is changing how people interact with data.
For years, the dominant pattern was clear: humans learned dashboards, SQL, BI tools, and data models in order to ask questions and get answers. But that model is starting to invert. Increasingly, people expect to ask questions in natural language, work through agents, and get outcomes, rather than navigate systems manually.
That sounds exciting. In practice, it exposes a hard truth:AI is only as useful as the context it can understand.
And enterprise data is one of the hardest forms of context to work with in software.
It is fragmented across warehouses, databases, and files. It is full of inconsistent naming, hidden business logic, tribal definitions, and semantic ambiguity. A language model may be powerful, but without the right structure, it still doesn’t know what “revenue,” “active customer,” or “pipeline” actually means inside your company.
The Problem We Saw from the Beginning
We didn’t start from the belief that companies needed “another database tool.”
We started from a much more specific observation: the missing layer for AI over business data is not just access. It is understanding.
Most systems can connect to a database. That is no longer the hard part. The hard part is turning raw, heterogeneous data into something an AI system can reliably reason over: what tables represent, how entities relate, which joins are valid, how metrics are defined, which fields are business-facing versus implementation detail, and what the trusted path to an answer should be.
Without that layer, AI built on data becomes fragile very quickly. It can generate SQL, but not always the right SQL. It can retrieve schemas, but not business meaning. It can answer simple questions, but breaks on the questions that matter most.
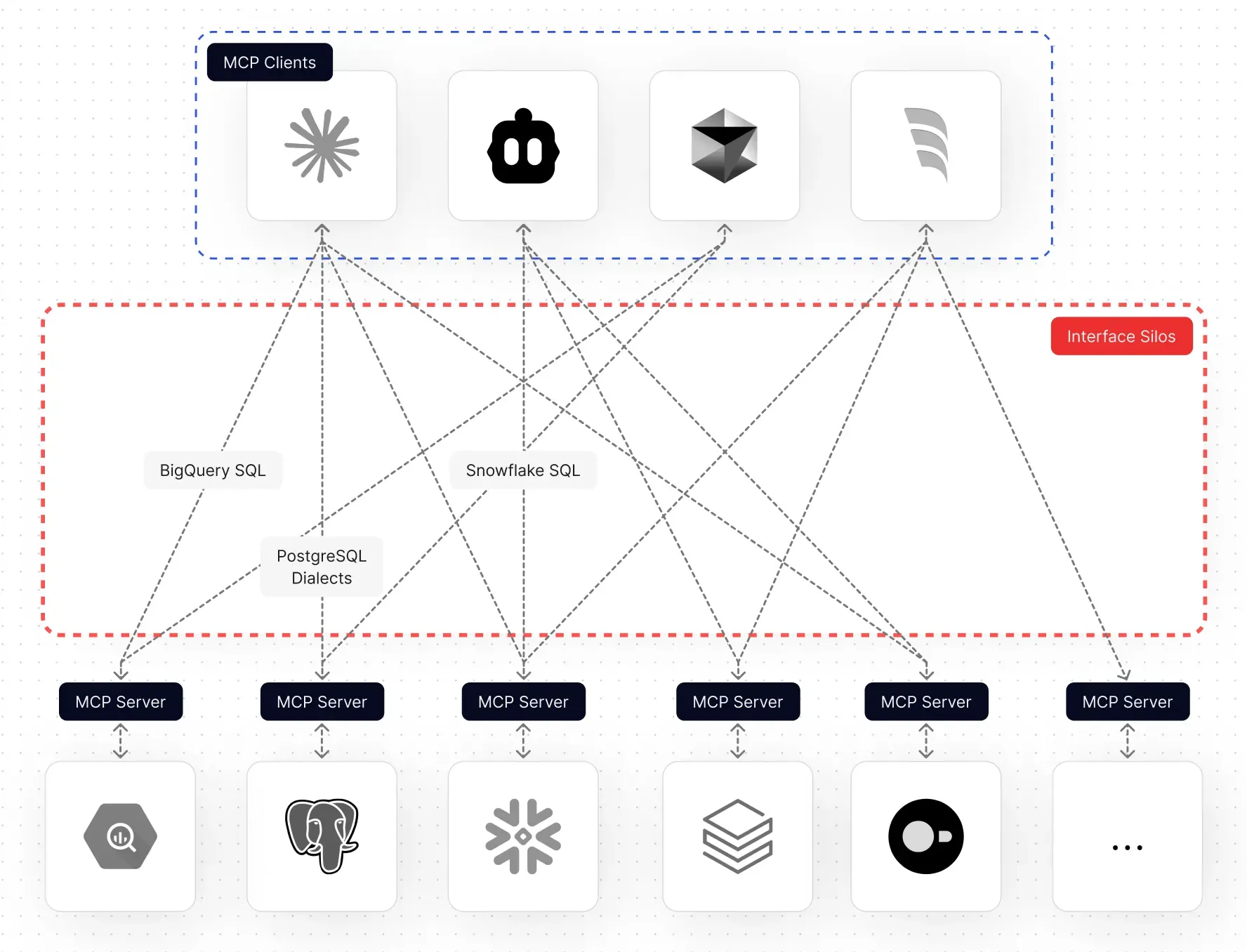
We believe there needs to be an engine that sits between raw data systems and intelligent applications. An engine that could provide not just connectivity, but a durable, governed, machine-readable understanding of data.
That idea became Wren Engine. The open-sourced context engine for AI agents supports 15+ data sources. MCP-native. Built on Rust and Apache DataFusion.
Why This Problem Matters Even More in the AI Era
In the pre-AI era, bad semantics created friction.
In the AI era, bad semantics create hallucination.
That is a profound difference.
When humans work directly with dashboards or SQL, they can often compensate for messy systems with judgment, context, and institutional knowledge. AI agents cannot do that consistently. If the underlying context is incomplete, the output becomes unreliable, no matter how good the model is.
This is not just our thesis. In Your Data Agents Need Context, a16z makes the case that the initial wave of enterprise AI agent deployments largely failed because agents lacked proper business context. As they put it, “data and analytics agents are essentially useless without the right context.” Teams tried to build “chat with your data” products on top of existing data stacks, only to discover that connecting an LLM to a database is not enough. The agent still couldn’t answer a basic question like “what was revenue growth last quarter?” because revenue is a business definition, not a column name, and that definition lives in tribal knowledge, outdated YAML files, and the heads of people who have since left the company.
a16z goes further, arguing that the problem extends well beyond text-to-SQL accuracy. Even as models have improved dramatically at code generation and reasoning, they still struggle with data tasks because the real bottleneck is not SQL generation. It is the absence of a structured business context: metric definitions, entity relationships, source-of-truth mappings, governance rules, and the operational knowledge that explains how a company actually runs.
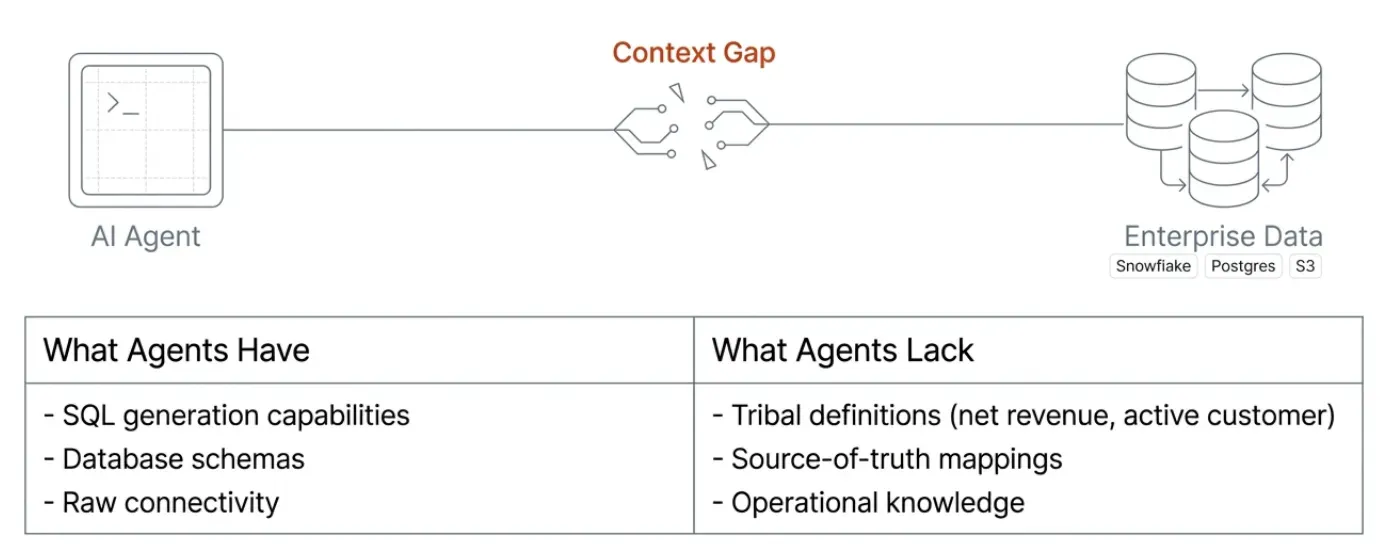
This is why we believe the next generation of the data stack needs something new. Not just a context layer in the old sense. Not just metadata documentation. Not just a query engine. Not just an LLM wrapper.
It needs a context engine: an open, semantic, governed layer that gives AI systems a structured way to understand business data, instead of relying on raw tables, columns, and prompts alone.
Wren Engine 1.0: What It Solved
Wren Engine 1.0 was built to solve an important first-generation problem: how do we make business data more usable through a context layer?
That first chapter mattered. It gave structure to raw data. It helped define models, relationships, and business-facing abstractions. In Wren’s modeling system, the core unit is the Model, a logical dataset backed by a physical table or query, with curated columns, primary keys, relationships, and calculated fields. That MDL-based structure created a cleaner bridge between physical data systems and analytical use cases.
That foundation remains important today.
But over time, we learned something critical: a context layer designed primarily for BI is insufficient for AI-native workflows.
Not because the original idea was wrong, but because the environment changed.
The a16z piece articulates this distinction well. Traditional semantic layers, as they note, are typically hand-constructed by data teams using a specific syntax such as LookML and are connected directly to a BI tool like Looker. They work for hard-coded metric definitions. But a modern context layer needs to become a superset of what semantic layers traditionally covered: not just metrics, but canonical entities, identity resolution, tribal knowledge, governance guidance, and more.
In a dashboard-centric world, the consumer of the context layer was usually a human or a BI tool. In an AI-native world, the consumer is increasingly an agent, a coding assistant, an MCP client, an application that needs structured context in real time, or a workflow that must span many systems, not just one analytics interface.
That shift changed the requirements dramatically.
Why We Rebuilt It: From Semantic Layer to Context Engine
Wren Engine 2.0 is our response to that shift.
We rebuilt Wren Engine because we no longer saw the problem as “how to define metrics better.” We saw it as: how do we make enterprise data legible, composable, and actionable for AI agents?
That requires a different design philosophy.
Today, Wren Engine is built on Rust and Apache DataFusion, designed to work across modern data stacks, including warehouses, operational databases, and file-based sources, with support for connectors such as Snowflake, Databricks, BigQuery, Redshift, PostgreSQL, MySQL, Oracle, SQL Server, Trino, ClickHouse, DuckDB, and others.
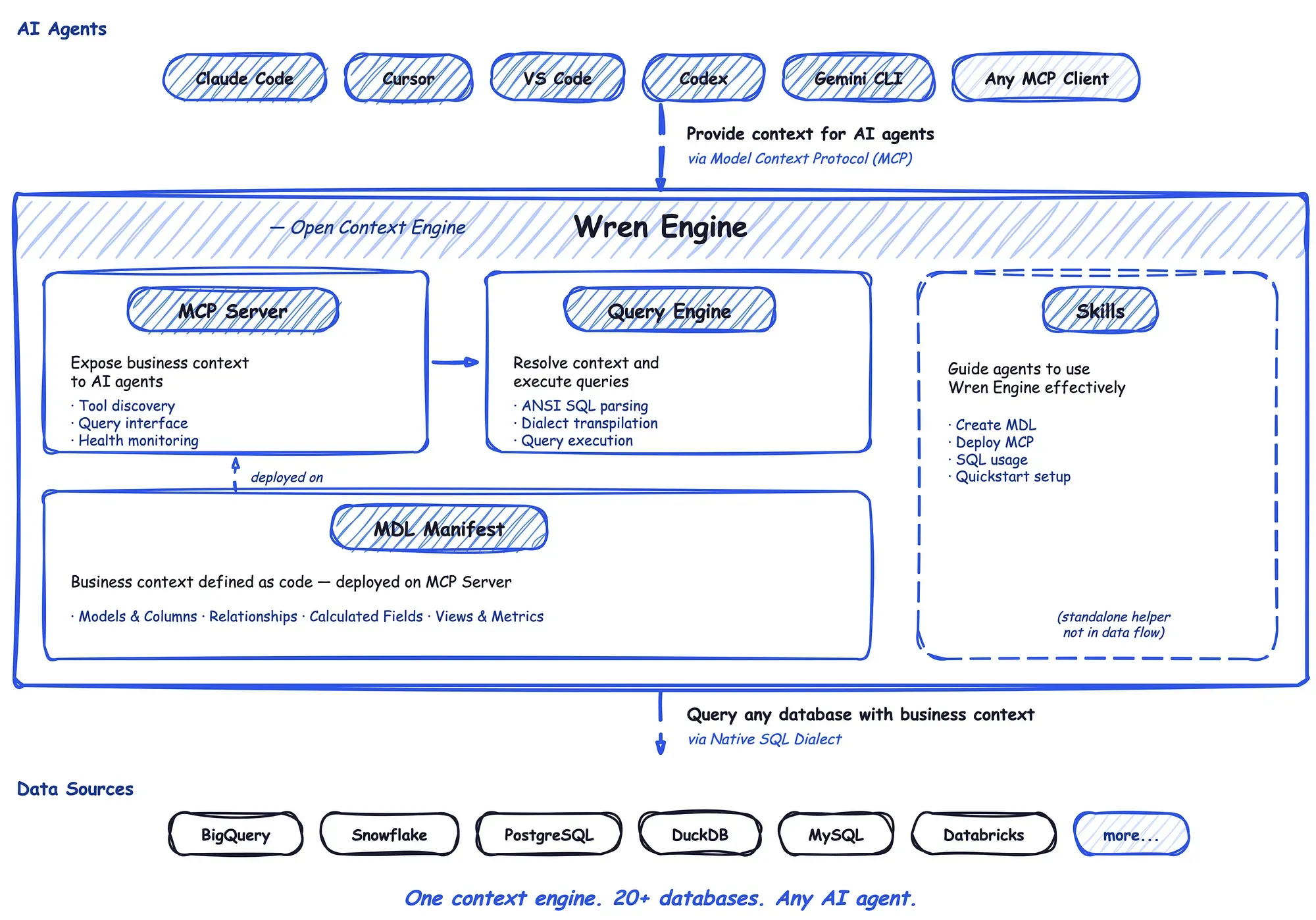
It is also explicitly MCP-native. The Wren Engine MCP server enables AI agents in environments like Claude Desktop, Cline, Cursor, VS Code, and other MCP clients to semantically understand and query business data. Agent-oriented skills handle connecting databases, generating MDL, and managing the MCP server, turning what used to be a manual setup into an agent-ready workflow.
That is not a cosmetic repositioning. It reflects a deeper architectural and product change.
What Changed: Wren Engine 1.0 vs. 2.0
The clearest way to describe the transition:
Wren Engine 1.0 asked: How can we model data better for analytics?
Wren Engine 2.0 asks: How can AI systems truly understand and operate on business data?
That leads to several major differences.
From BI-first to agent-first. Wren Engine 1.0 was rooted in the semantic modeling tradition. Wren Engine 2.0 is designed for the world of agents. The engine is no longer just a backend layer for dashboards or SQL generation. It becomes infrastructure for any AI system that needs a structured business context.
From single-interface thinking to ecosystem thinking. The old world assumed one destination: a BI interface. The new world is multi-surface by default: AI assistants, agent frameworks, developer tools, embedded copilots, internal workflows, and applications built on top of business data. A context engine has to serve all of them.
From metadata as documentation to metadata as execution context. Traditional metadata often helps humans discover meaning. Wren Engine 2.0 treats modeled context as something AI systems can directly use to reason, plan, and act. The context can’t just be descriptive. It has to be operational.
From closed workflow assumptions to open infrastructure. Wren Engine is now an open context engine, with open-source distribution under Apache 2.0 and public interfaces. That matters because AI ecosystems move fast. The winning infrastructure layer cannot assume one UI, one model provider, or one orchestration pattern.
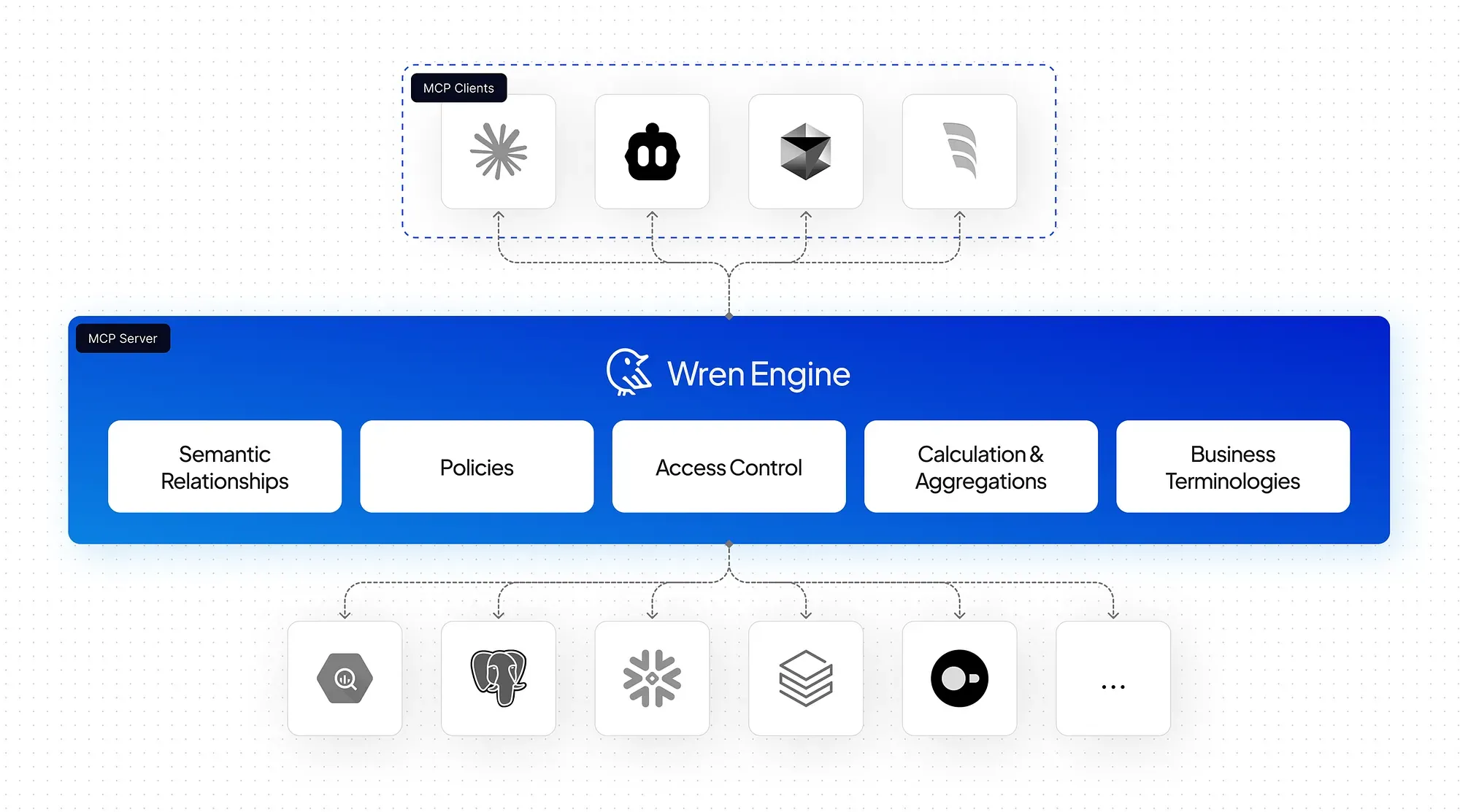
From “context layer” as a category to “context engine” as a category. We don’t think the future category is limited to semantic layers as people traditionally understood them. The emerging category is broader: a machine-readable, governed, extensible context layer for AI systems. That is what we mean by Wren Engine.
Why the Technical Redesign Matters
We also rebuilt the engine technically to match the ambition.
Wren Engine is built on Rust and Apache DataFusion, and that choice is deliberate. Performance and systems-level reliability matter when this becomes core infrastructure. Modern query execution matters when serving heterogeneous data environments. Extensibility matters when new connectors and agent surfaces are arriving constantly. And openness matters when developers want to build around the engine, not just use it passively.
The semantic engine enables three key capabilities that set it apart from raw database MCP servers or text-to-SQL agents:
Semantic Modeling. You define your business logic, relationships, metrics, and KPIs in a structured, graph-based format using MDL. This semantic model maps natural language requests to the correct data with precision.
Real-Time SQL Rewrite. Using metadata and user context, Wren Engine rewrites AI-generated SQL in real time, applying necessary joins, filters, calculations, and access controls.
Agent-Ready Architecture. Whether through MCP, HTTP APIs, or embedded as a service, Wren Engine can become the context layer behind any agent. The flow is straightforward: user or agent → MCP client or app → Wren MCP server or HTTP API → Wren Engine semantic engine → query planning and optimization → your warehouse, database, or file-backed data source.
If Wren Engine is going to become a foundational layer for agentic data systems, it cannot just be conceptually right. It has to be operationally strong.
Our Belief About the Future
We believe the future of data will not be defined by dashboards alone. It will be defined by systems that can turn business intent into reliable action.
In that world, users will ask questions conversationally. Agents will plan and execute across data systems. Applications will generate insights dynamically. Models will need a grounded, governed business context. And structured enterprise data will become one of the most important substrates for AI.
The a16z piece describes a vision where automated context construction, human refinement, and self-updating context flows come together to create a living, evolving layer that agents can rely on. We share that vision. And the key enabling layer will be the engine that makes that context usable.
That is the future we envision for Wren Engine. Not just as a product feature, not just as a semantic modeling tool, but as a foundational layer for the next generation of AI-native data infrastructure.
What Comes Next
Our long-term vision is for Wren Engine to become the standard context layer between enterprise data and AI systems. Here is where we are focusing next.
The Open Context Layer for AI.
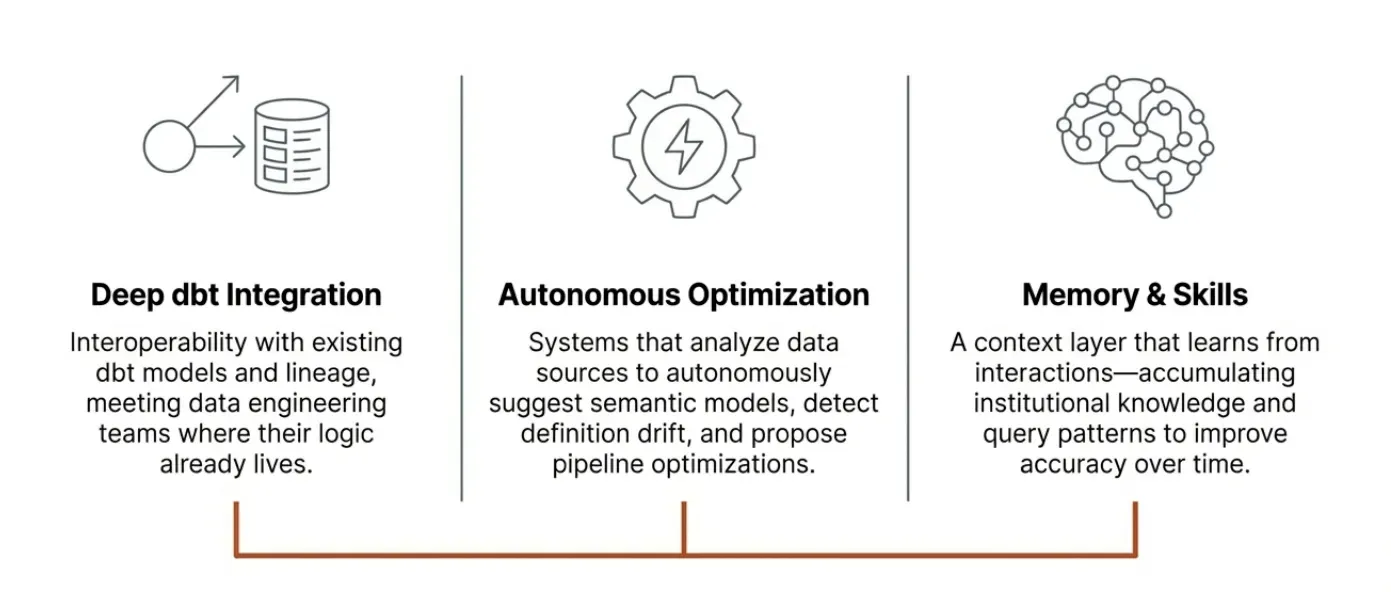
Deeper integration with dbt. dbt has become the standard for data transformation and modeling in modern data teams. We are building deeper interoperability between Wren Engine and dbt, so that teams can leverage their existing dbt models, definitions, and lineage as first-class inputs to the context layer. If you’ve already invested in dbt to define your business logic, Wren Engine should meet you where you are, not ask you to start over.
Native optimization with AI coding agents. The developer workflow is shifting toward agent-assisted environments like Claude Code, Cline, Cursor, and VS Code. We are making Wren Engine a natural part of those workflows. When an AI coding agent needs to query business data, generate reports, or build data-driven features, Wren Engine should be the context layer it reaches for automatically through MCP, not something that requires manual configuration.
Autonomous semantic and modeling optimization. Today, setting up and maintaining a semantic model still requires significant human effort. We are working toward a future where Wren Engine can autonomously analyze your data sources, suggest and refine semantic models, detect drift in definitions, and propose optimizations. The goal is not to remove human oversight, but to reduce the manual burden of keeping context accurate and up to date, so your team focuses on validation rather than construction.
Memory and skills for the context layer. Context is not static. Business logic evolves, new data sources appear, and teams refine how they define metrics over time. We are implementing memory and skills into Wren Engine so that the system learns from interactions: remembering past query patterns, accumulating institutional knowledge, and developing reusable skills that improve accuracy over time. Think of it as giving the context engine the ability to get smarter the more your team uses it.
Open ecosystem leverage. We want developers, partners, and AI builders to treat Wren Engine as infrastructure they can compose into their own products and workflows. Agent infrastructure should be inspectable, composable, and community-owned, not trapped inside a single proprietary interface.
Enterprise-grade trust. If this layer becomes the ground truth for AI over data, it must be governed, transparent, and reliable by design.
Why We Are Building This Now
Every so often, a new interface forces the software stack beneath it to be rebuilt. AI is one of those moments.
People often focus on the model. We think the more enduring opportunity is the layer that makes models useful in the real world. For business data, that layer is context.
That is why we started Wren Engine. And that is why Wren Engine 2.0 is not just an iteration. It is a statement of belief:
The future of AI over data will belong to systems that understand context, not just syntax.
Get Involved
Wren Engine is open source under Apache 2.0. We are building this in the open because we believe the context layer for AI should be inspectable, composable, and community-owned.
⭐ Star and explore the repo on GitHub →
💬 Join our community on Discord →
Whether you’re a data engineer frustrated with brittle AI queries, an agent developer looking for reliable business context, or an open-source contributor who wants to shape the future of AI infrastructure, we’d love to have you.
Come build with us.
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free TrialRelated Posts
AI-Powered Business Intelligence: The Complete Guide to GenBI
Discover how Generative Business Intelligence (GenBI) powered by Wren AI is transforming data access with conversational AI, real-time insights, and intuitive decision-making tools for modern enterprises
Jan 17, 2025Forward to 2025 Powering the Future of Enterprise with AI-Driven Data Intelligence
A Year of Wren AI Growth and Vision for the Future
Jan 09, 2026The Future is a Data Fabric and Mesh, Woven by AI Agents
Why the Future of Enterprise Data Mesh and Fabric Relies on Autonomous AI Agents and a Universal Semantic Protocol.

Keep reading
 Insight
InsightAI-Powered Business Intelligence: The Complete Guide to GenBI
Discover how Generative Business Intelligence (GenBI) powered by Wren AI is transforming data access with conversational AI, real-time insights, and intuitive decision-making tools for modern enterprises
 News
NewsForward to 2025 Powering the Future of Enterprise with AI-Driven Data Intelligence
A Year of Wren AI Growth and Vision for the Future
 Trend
TrendThe Future is a Data Fabric and Mesh, Woven by AI Agents
Why the Future of Enterprise Data Mesh and Fabric Relies on Autonomous AI Agents and a Universal Semantic Protocol.