You Can't Trust an AI Agent You Can't Debug
An AI agent that answers business questions has to be debuggable and measurable, or 'earned trust' is just a slogan. How thread tracing, benchmarks, and the AI Advisor close the loop.

Wren AI Product Team
Updated: Jun 29, 2026
Published: Jun 29, 2026

An AI agent answers a business question. The number looks plausible. Someone acts on it. Three weeks later you discover it was wrong. It used the wrong join, or an outdated definition, or it misread an ambiguous question.
Now multiply that across hundreds of questions a week. If you can't answer why the agent said what it said, and you can't tell whether last week's fix made things better or worse, then "trust our AI" is a request, not a property. You're asking people to believe.
A human analyst earns trust differently. They show their work. You can ask "where did this number come from," they can be corrected, and they get measurably better over time. An agent that's going to sit in that seat has to do the same three things: be inspectable, be correctable, and be measurable. That's not a feature checklist. It's the whole basis of whether anyone should believe the output.
"Trust our AI" is a slogan. "Here's exactly how it got that number, here's where you correct it, and here's the benchmark proving it improved" is a system. We built the second one.
Inspectable: every answer is a trace, not a black box
When the agent returns an answer. It interpreted the question, picked a definition, planned a query, and executed it. Thread tracing records that path, so when a number looks off, you don't argue about it. You open the trace and look.
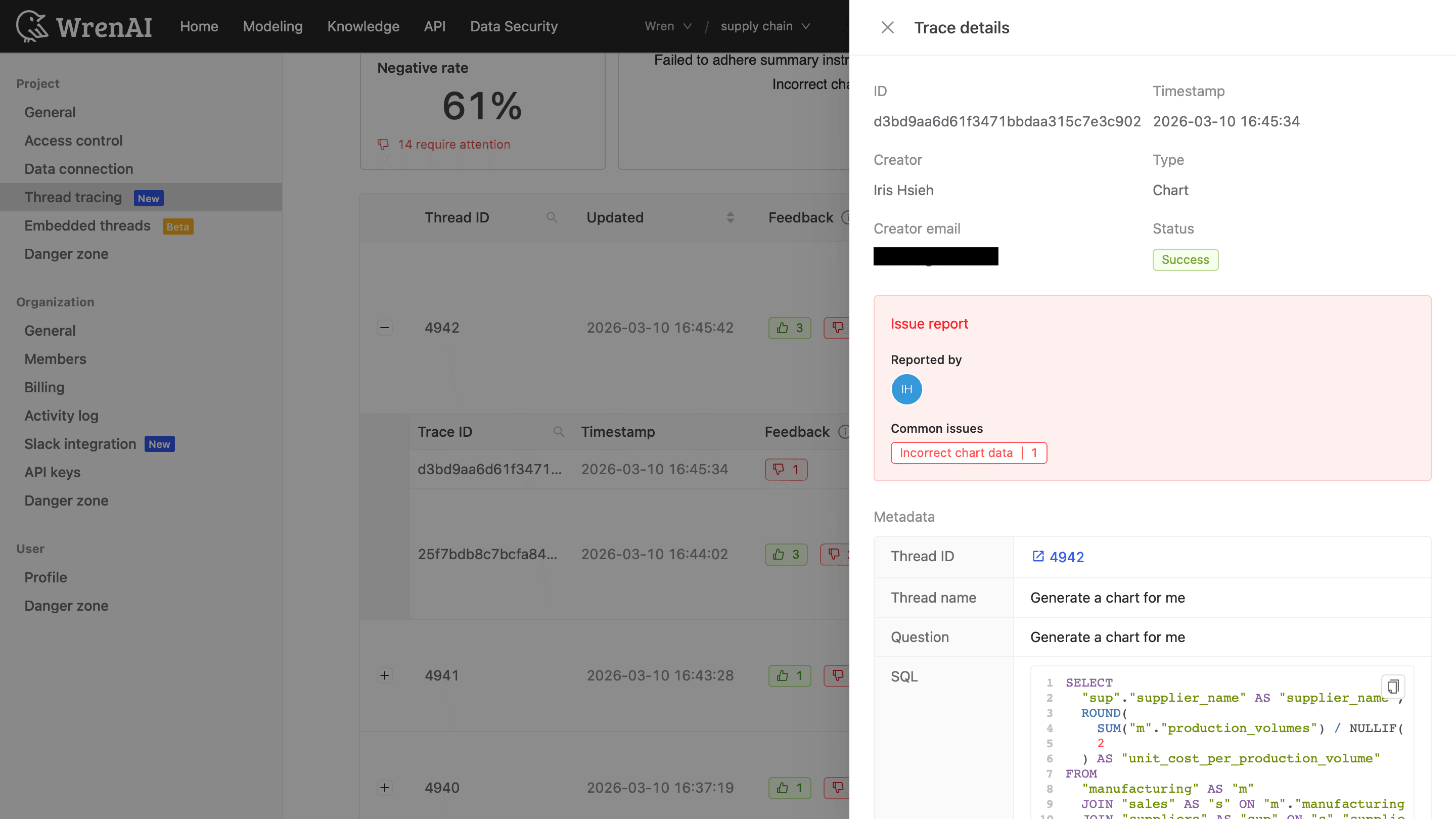
This is the difference between "the AI got it wrong" and "the AI joined orders to shipments on the wrong key, here, on this step." The first is a reason to abandon the tool. The second is a bug you can fix. Observability is what turns a mysterious wrong answer into an ordinary engineering problem.
Correctable: feedback is a loop, not a complaint
Inspecting the failure is half of it. The other half is doing something with it. When someone flags an answer as wrong, that correction doesn't vanish into a support queue. It becomes structured feedback attached to the thread.
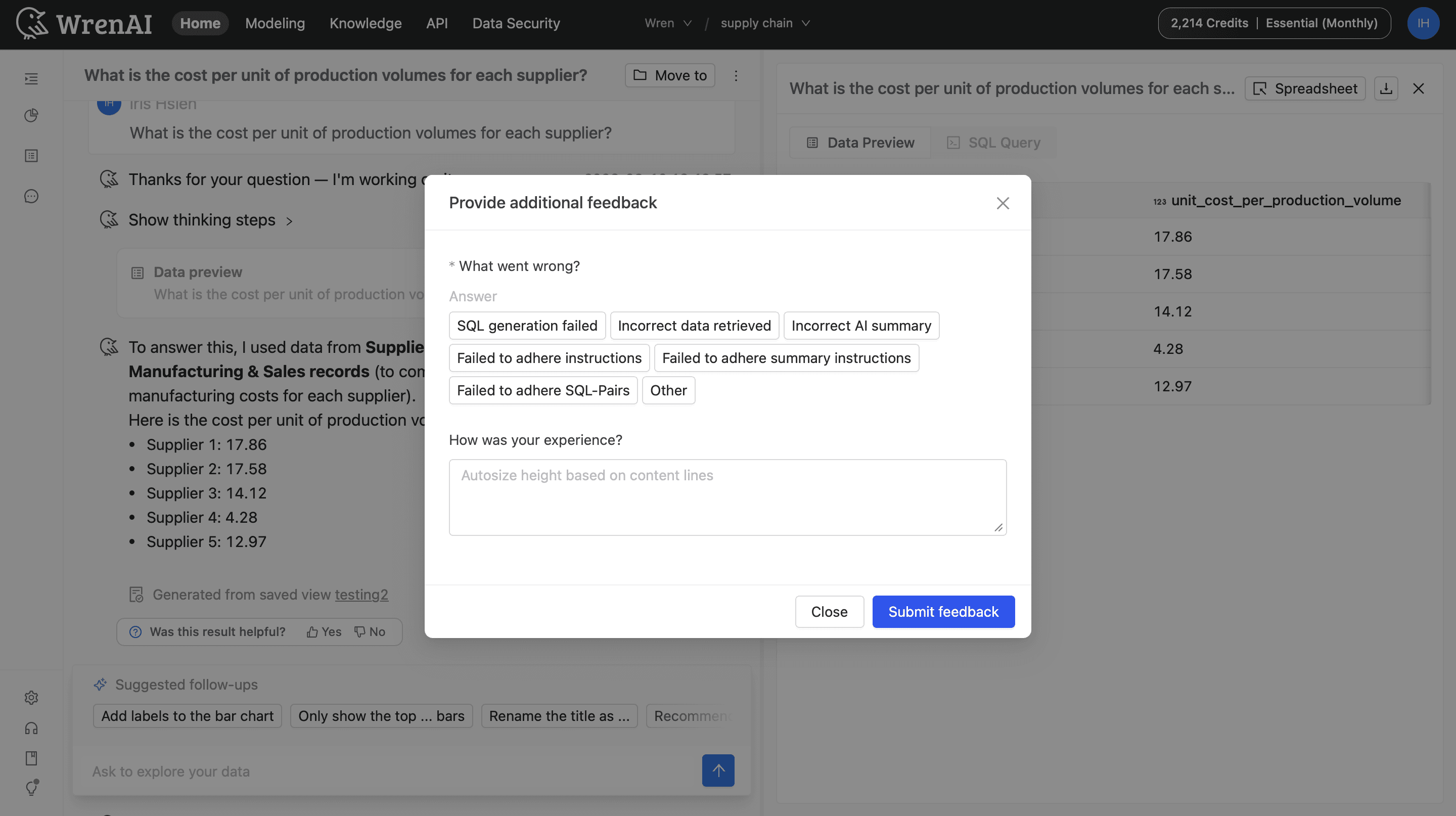
That's the data-driven loop. A correction on Monday becomes a signal that improves how the agent handles that class of question, instead of the same mistake resurfacing on Friday for the next person. It's the same principle as the Memory layer I wrote about earlier in this series: the system has to keep what it learns from being corrected, or it's day-one wrong forever. Feedback that compounds is how an agent stops repeating itself.
Measurable: benchmarks, or you're just guessing
Here's where most "AI for analytics" stories go quiet, because it's the hard part. You changed a metric definition, added a few knowledge instructions, tweaked the model. Did accuracy go up or down? If you can't answer that with a number, you're not improving the system. You're stirring it.
So Wren AI treats agent quality the way you'd treat any production system: with a benchmark suite. You assemble a set of real questions with known-correct answers, run the agent against them, and get a score, not a vibe.
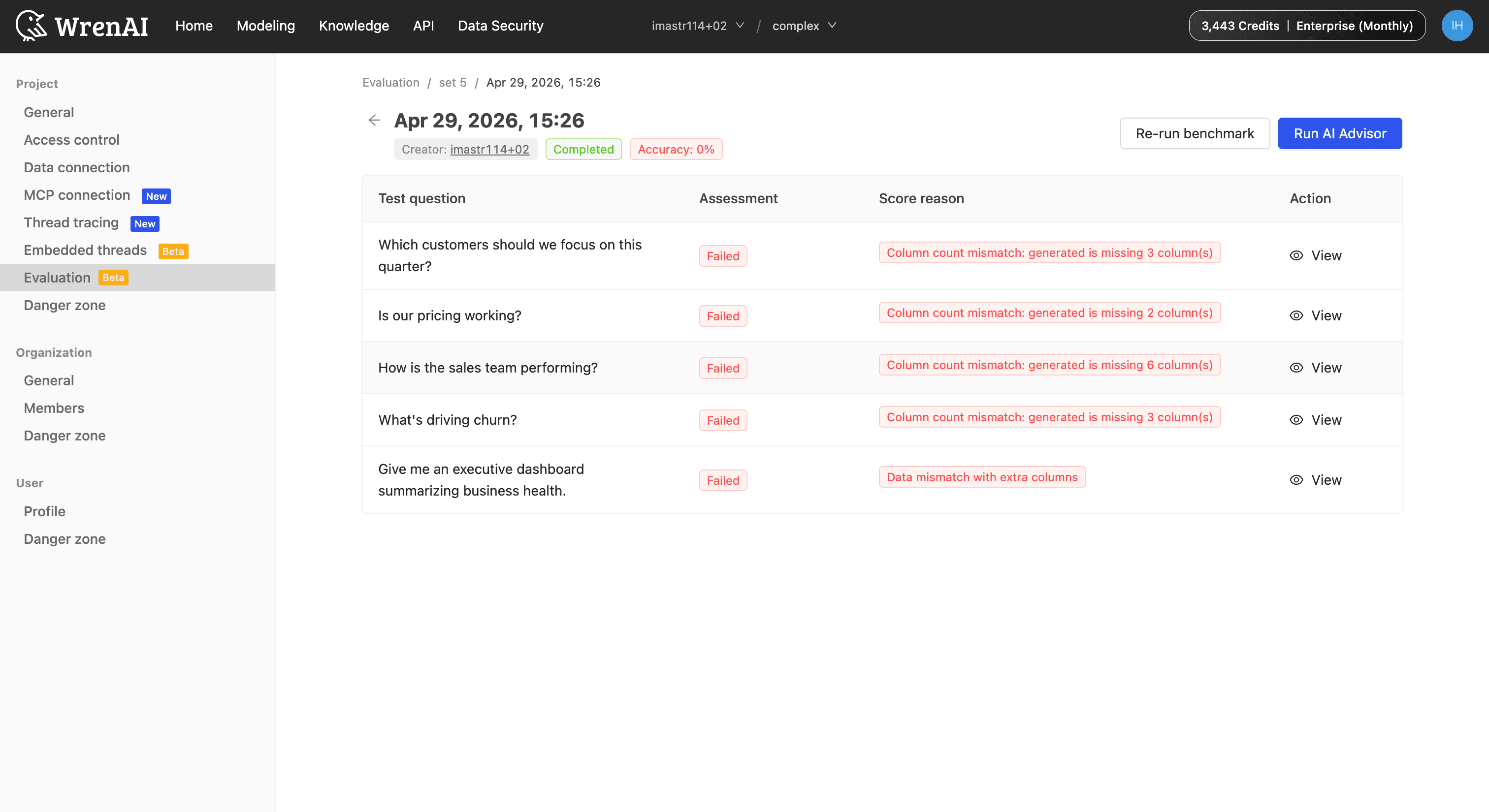
When something regresses, the diagnosis shows you which questions broke and why, down to the SQL difference between what the agent produced and what was expected.
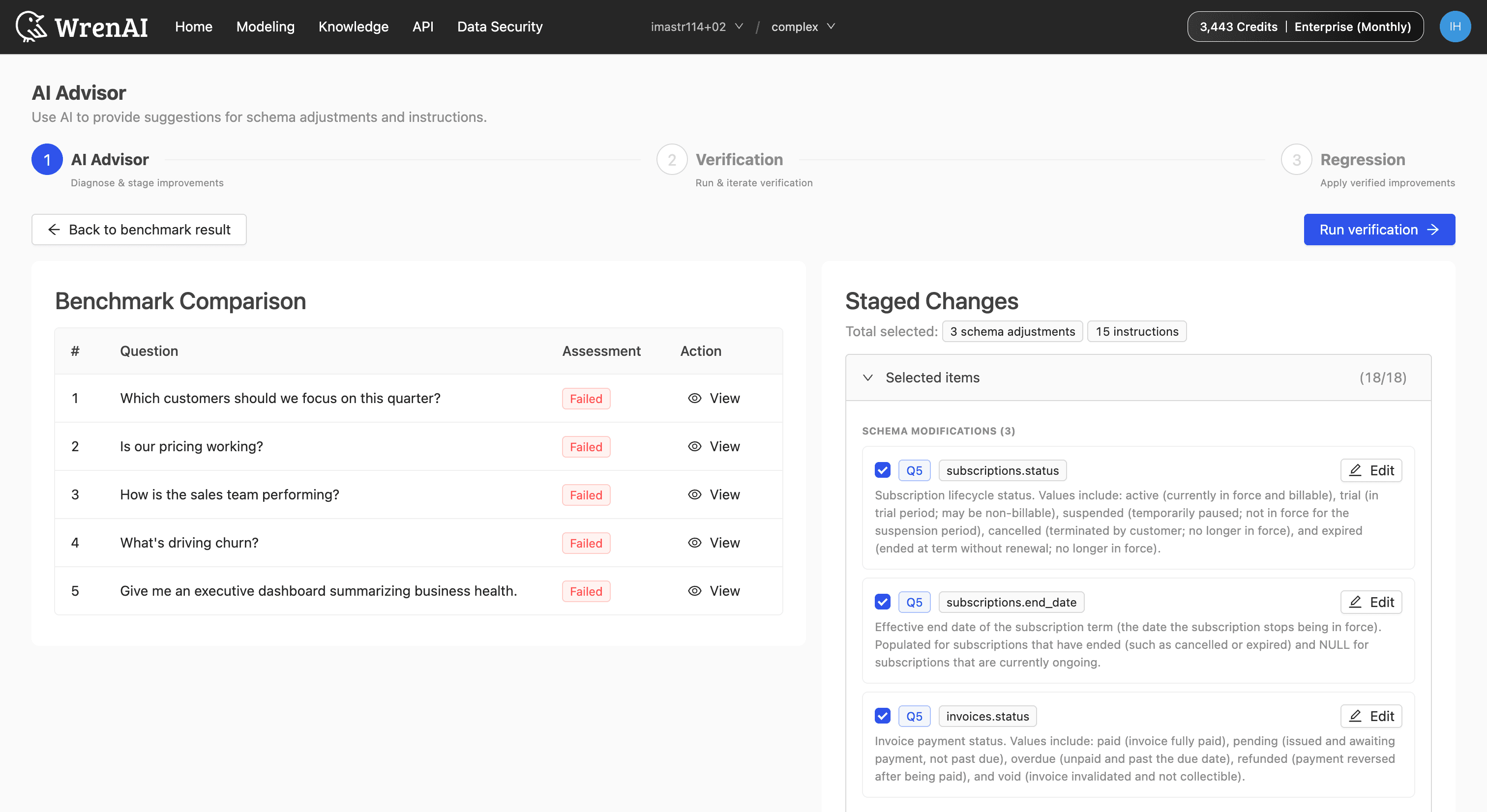
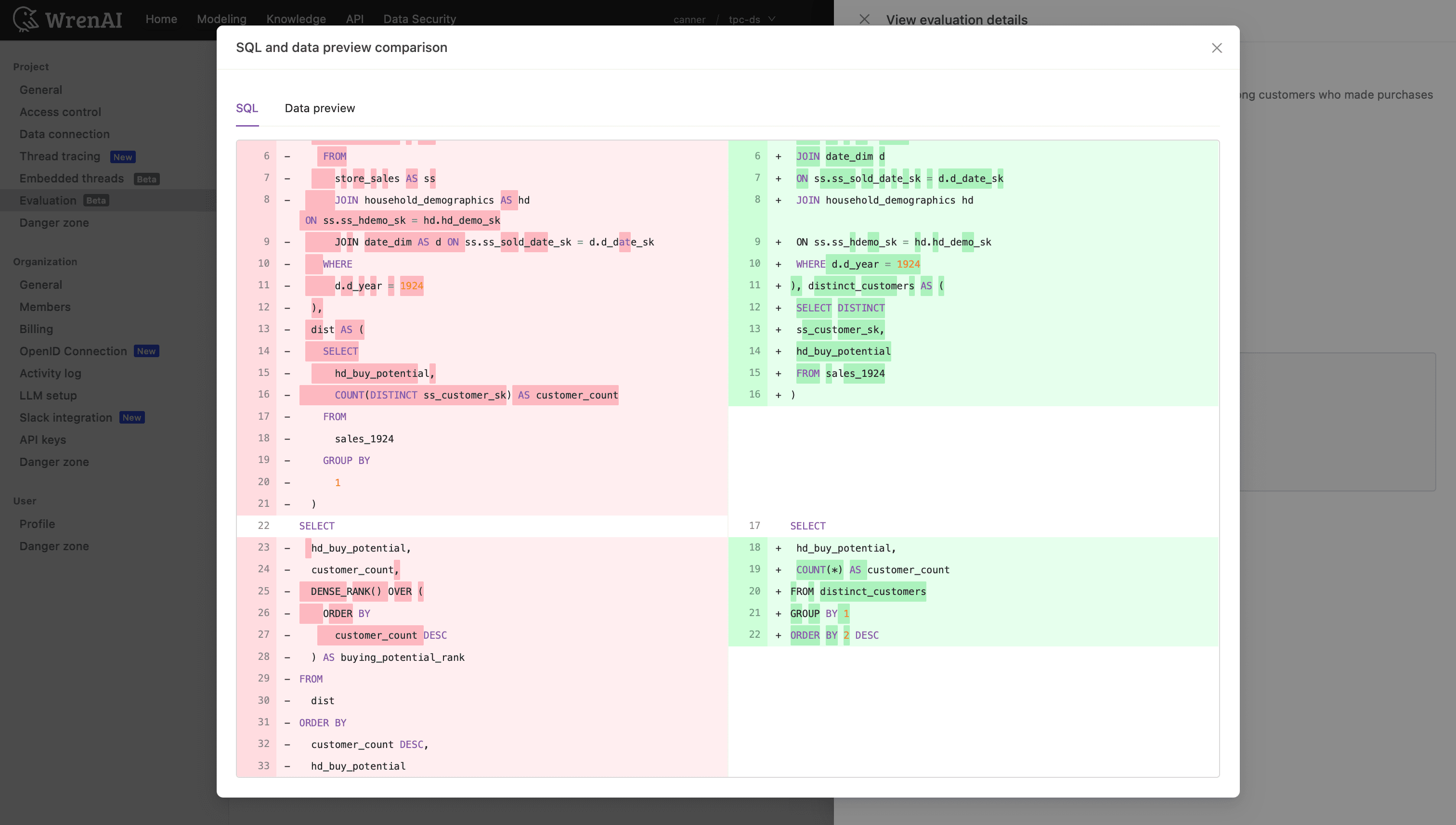
And because nobody has time to manually hunt every regression, the AI Advisor analyzes the failures and recommends concrete fixes to your semantic model and knowledge, so improving accuracy becomes a guided workflow, not an archaeology dig. You run the benchmark, you see what broke, you apply the recommended fixes, you re-run, you watch the number go up. That's a quality process. That's what "earned trust" actually means when you build it instead of saying it.
The unsexy half of Agentic GenBI, and the half that matters
The demos that go viral are the magic ones: ask a question, get a chart, gasp. But the reason most "chat with your data" tools never make it past the pilot isn't that the magic doesn't work. It's that nobody can trust it in production, because when it's wrong, and it will sometimes be wrong, there's no way to see why, no way to correct it, and no way to prove it's getting better.
An agent reasoning over a governed context layer is the foundation. Tracing, feedback, and evaluation are what make that foundation operable by a real team. They're the difference between a tool you demo and a tool you deploy. You can't put an agent in front of decisions people act on and ask them to just believe. You have to show the work, take the correction, and prove the improvement.
Earned trust isn't a tagline. It's a trace you can open, a correction that sticks, and a benchmark that goes up. Build those three, and the agent gets to do what an analyst does: be believed, because it earned it.
Wren AI core is open source. → getwren.ai
Part of the Agentic GenBI series. See also Introducing Agentic GenBI and "Your AI Agent Has Amnesia" on the Memory layer.
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free Trial