GenBI for AI Agents: Why We Rebuilt Wren AI Around an Open Context Layer
The consumer of analytics is becoming the agent, and agents need your business's meaning in a form they can read. A founder's case for the open context layer, and why we rebuilt Wren AI OSS around it.

Howard Chi
Updated: Jun 22, 2026
Published: Jun 22, 2026

Every BI vendor is bolting a chat box onto a dashboard and calling it AI. I think that's backwards, and I think it's about to look obviously backwards.
The chat box assumes the consumer of analytics is still a human reading a chart. For twenty years, it was. You built a dashboard, a person looked at it, a person decided something. The whole stack was designed around that last mile being a pair of human eyes. The modeling, the metrics, the BI seats, all of it.
That last mile is changing. The thing asking your data a question is increasingly an agent: Claude in your analyst's terminal, a copilot inside your product, a vendor's agent in your workflow tool. And an agent doesn't want a prettier dashboard. It wants to know what "revenue" means at your company, which tables to join, and which rows it's allowed to see, in a form it can read directly.
Agents don't need a BI tool. They need your business's meaning as machine-readable context: an open layer that sits between your data and any agent, giving every one of them the same understanding of what your numbers mean.
That's the bet we just rebuilt Wren AI OSS around, and it's the biggest change to the project since we started it.
For most of its life, Wren AI was a GenBI chat app you logged into. The latest release inverts that. We moved the semantic engine into core/, retired the old chat UI to a legacy branch, and made the open context layer the product itself. Wren AI is no longer a place people go to ask questions. It's the layer your AI agents reason through, governed by files you own. That's what "GenBI for AI agents" means in practice, and it's the narrative the whole project now runs on.
Let me explain what changed and why I think this is the shape of the next decade of BI.
First, for anyone new to Wren AI
If Wren AI is new to you, here's the short version. It's an open-source project, Apache-2.0, that we've built in public for the last two years, and it now has 15.6k stars on GitHub: github.com/Canner/WrenAI. It sits between your databases and the tools that ask them questions: it holds your models, joins, and definitions, then turns a plain-English question into governed SQL across 22+ data sources. The point was always the same. Let people get answers from their data without hand-writing SQL or memorizing a schema.
As for why I'm writing this now: we just shipped a release that changes what Wren AI fundamentally is, and a changelog can't carry a shift that big. I wanted the reasoning in one place, the bet and why we made it, so the pieces below read as a single argument instead of a feature list. So let me start where the need actually comes from.
The problem: agents are flying blind, and we're calling it hallucination
Here's what actually happens when you point an agent at your warehouse today.
You hand it a schema: table names, column names, types. You hope it figures out the rest. And it tries. It guesses that rev_net is the revenue number finance trusts, it invents a join, it quietly includes test accounts because nobody told it not to. Then it answers with total confidence, and we call the wrong number a "hallucination," as if the model failed, when really we never gave it the context to succeed.
The meaning was never in the schema. It was in people's heads, in a decade of dashboards, in tribal knowledge no agent can reach.
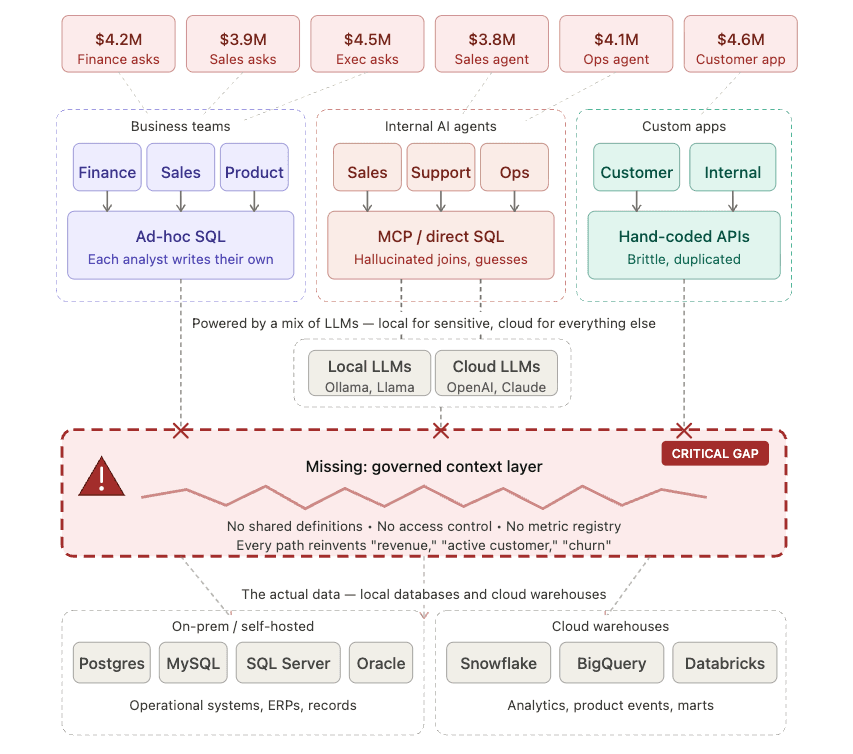
A company where forty agents each invented their own definition of revenue isn't data-driven. It's forty confident, conflicting wrong answers, produced at machine speed, landing in decisions before a human reviews them. The bottleneck of the agentic era isn't model quality. It's context.
What we rebuilt: Wren AI as an open context layer
So we made a decision that, a year ago, would have sounded strange for a BI company: we stopped putting our own UI first.
In the recent restructure, the Wren semantic engine moved into core/, and the old Docker chat interface became "GenBI Classic," still there on a legacy branch, but no longer the center of gravity. The center of gravity is now the context layer itself: a thing agents talk to, not a place people log in to.
The pieces that matter:
-
MDL, your business in version-controlled files. Models, relationships, calculated fields, and the definitions your finance team would go to war over, all written down in a Modeling Definition Language you can review in a pull request. Your business logic stops being tribal knowledge and becomes an asset you own, diff, and govern. Not locked in a vendor UI. In your repo.
-
A semantic engine that plans real SQL. The Rust core, built on Apache DataFusion, takes a modeled question and produces governed, executable SQL across 22+ sources: BigQuery, Snowflake, Databricks, ClickHouse, Postgres, and the rest. Same definitions, same access rules, whether the question came from a person or an agent.
-
Skills that make agents safe to point at data. Structured workflows like
generate-mdlandgenbiso an agent enriches context and builds dashboards through guardrails like dry-plan validation, structured errors, and access control, instead of free-styling raw SQL against production. -
It works through the agents you already use. Claude Code, Cursor, Cline, LangChain, Pydantic AI. Wren is the context layer they call, not another tool you have to adopt and train people on.
How a question actually flows through Wren
The whole argument lives or dies on one detail: where the question goes before it hits the database. So follow one.
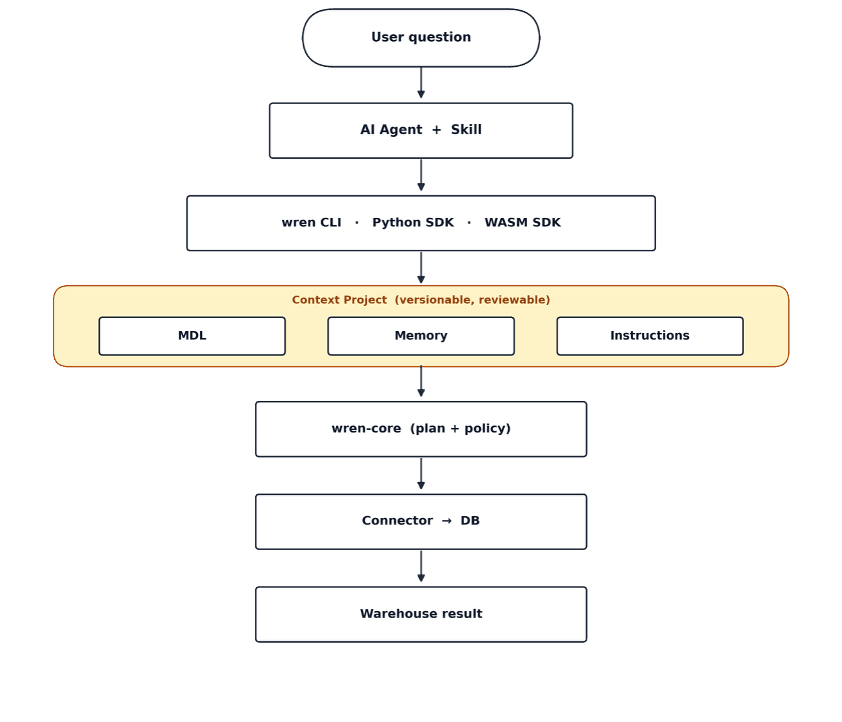
A user question comes in and hits an AI Agent + Skill. The Skill is the guardrail that keeps the agent on the rails instead of free-styling SQL. The agent calls Wren through the CLI, the Python SDK, or the WASM SDK, depending on whether it's running in a terminal, a backend, or a browser.
Then comes the part nobody else makes a first-class thing: the Context Project. This is where MDL, Memory, and Instructions live: your models, what the system has learned from past corrections, and the standing rules for how your business is read. It's marked versionable, reviewable on purpose. Your business meaning is a project in your repo, reviewed in a pull request, not a string buried in someone's prompt.
Only after the question is grounded in that context does wren-core plan it, applying both the query plan and your access policy in the same step, then hand governed SQL to the connector, which runs it against your database and returns the warehouse result.
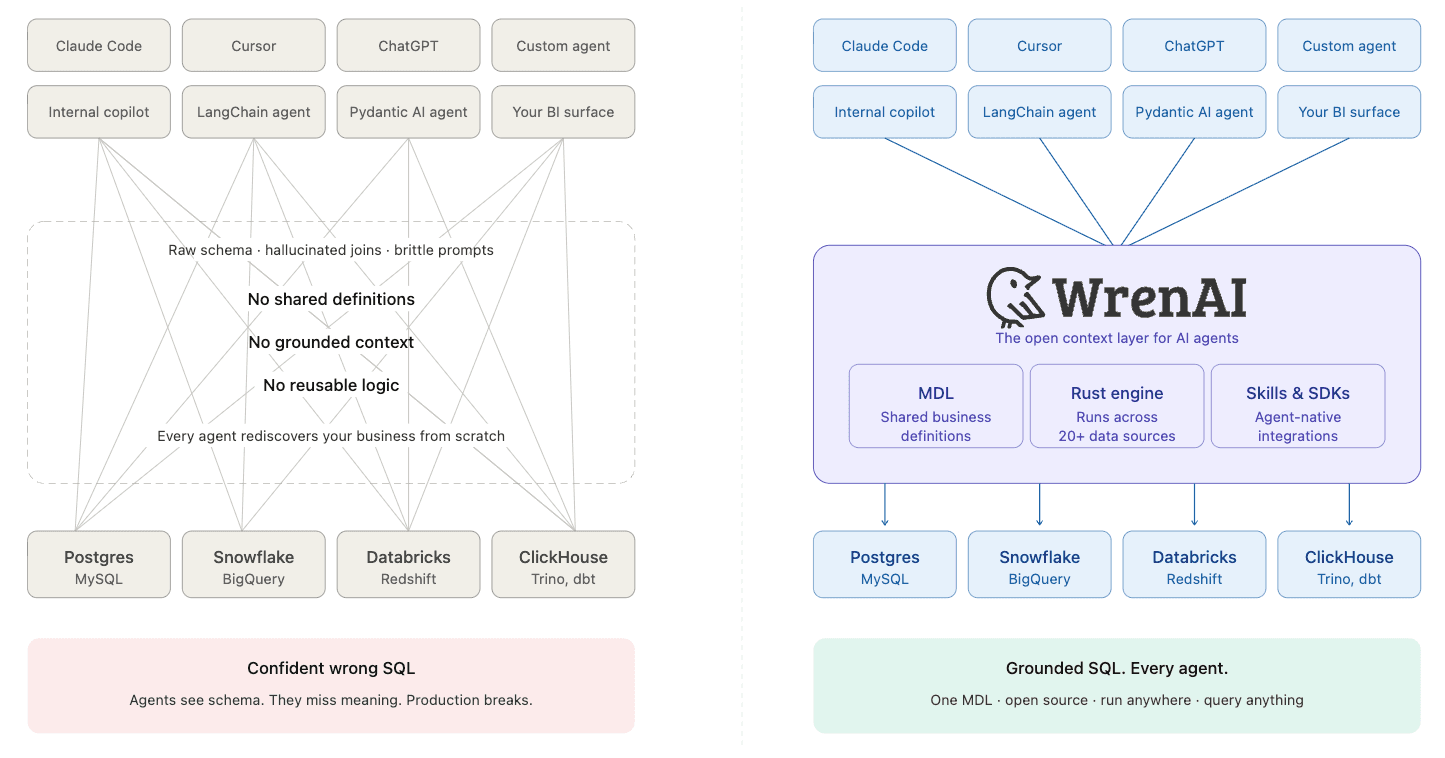
Look at the order. Every other "AI on your data" tool draws an arrow straight from the question to the database. The entire value of Wren is the box in the middle that they leave out.
That middle box is the difference between an agent that guesses and one that knows. And because it's a reviewable project, it's also the difference between business logic you own and business logic you rent.
The mental model: Generate, Deploy, Know
If you take one frame from this post, take this one. GenBI is three beats, and the third is the one everyone skips.
Generate. An agent turns a plain-English question into governed SQL and a chart, using your models, your joins, your definitions.
Deploy. The answer ships as a shareable, browser-side dashboard. Because the semantic engine compiles to WebAssembly, the dashboard carries its own logic, with no server round-trip to render it. The dashboard becomes disposable output, not infrastructure you maintain.
Know. This is the one. The business meaning gets captured back into the context layer: definitions, instructions, corrections, the feedback from the last wrong answer. Every agent that asks tomorrow inherits what was learned today. The context compounds. The dashboards depreciate.
And "Know" isn't a static file you write once. It's a loop.

Walk it. A new question comes in. Wren fetches the relevant context, the MDL and instructions that say what your terms mean. Then it does the part static semantic layers can't: it recalls confirmed examples, the accepted question-to-SQL pairs from every time someone validated an answer before. It generates grounded SQL using both. And when that answer is accepted, it stores it, so the next similar question recalls a known-good pattern instead of reasoning from scratch.
That's the difference between context that sits still and context that learns. A metrics layer gives an agent the same starting point every day. This gives it a memory. Every correction your team makes is a permanent upgrade to every agent's next answer, not a note someone has to remember to apply.
"Isn't this just a semantic layer? Isn't this just MCP?"
Two fair objections, so let me take them directly.
"We already have a semantic layer." Most semantic layers were built to serve a BI tool's dashboards: one consumer, one product, definitions effectively trapped inside it. The context an agent needs is wider than metrics. It's structural (tables, keys), semantic (models, calculations), business (what terms mean), operational (join paths, governance), and behavioral (memory, feedback). A metrics layer covers one of those five. An agent needs all five, and it needs them open.
"MCP already lets my agent reach my data." A connection isn't comprehension. MCP is great plumbing. It lets an agent call a tool and get a result back. But if the thing on the other end of that pipe is a raw schema, you're back to guessing. The context layer is what makes the pipe worth having: it's the difference between an agent that can query your data and one that queries it correctly.
The villain here was never the agent, and it was never the model. It's twenty years of business meaning locked inside dashboards and vendor UIs, in a decade where everything reasoning over your data needs to read it.
Why this is the bet
I believe the most valuable thing most companies own in five years won't be their dashboards or even their data. It'll be the context layer that tells every agent what their data means, and whether they own that layer or rent it back from a vendor.
We built Wren AI in the open, Apache-2.0, on purpose. A context layer that every agent in your stack reasons over is too important to be a black box you can't inspect, fork, or move. v0.10.1 shipped today. 15.6k developers have starred it. If the agentic future is going to run on your business's meaning, that meaning should live somewhere you can read it too.
So here's the one ask: if this is the right bet, star Wren AI on GitHub and put the context layer in front of one of your agents this week. Point Claude Code or Cursor at it, model one domain, and watch the difference between an agent that guesses and one that knows.
The dashboard isn't the product anymore. The context is. Build the layer your agents will reason over, and own it.
Supercharge your data with AI today
Join thousands of data teams already using Wren AI to make data-driven decisions faster and more efficiently.
Start Free Trial